
At A Glance
- AI pilots fail to scale not because they are wrong, but because they are incomplete
- The gap between pilot and production is operational, not just technical
- Trust, explainability, governance, and integration determine adoption
- Leading institutions design for production from the outset
- AI must align with real decision systems to deliver sustained impact
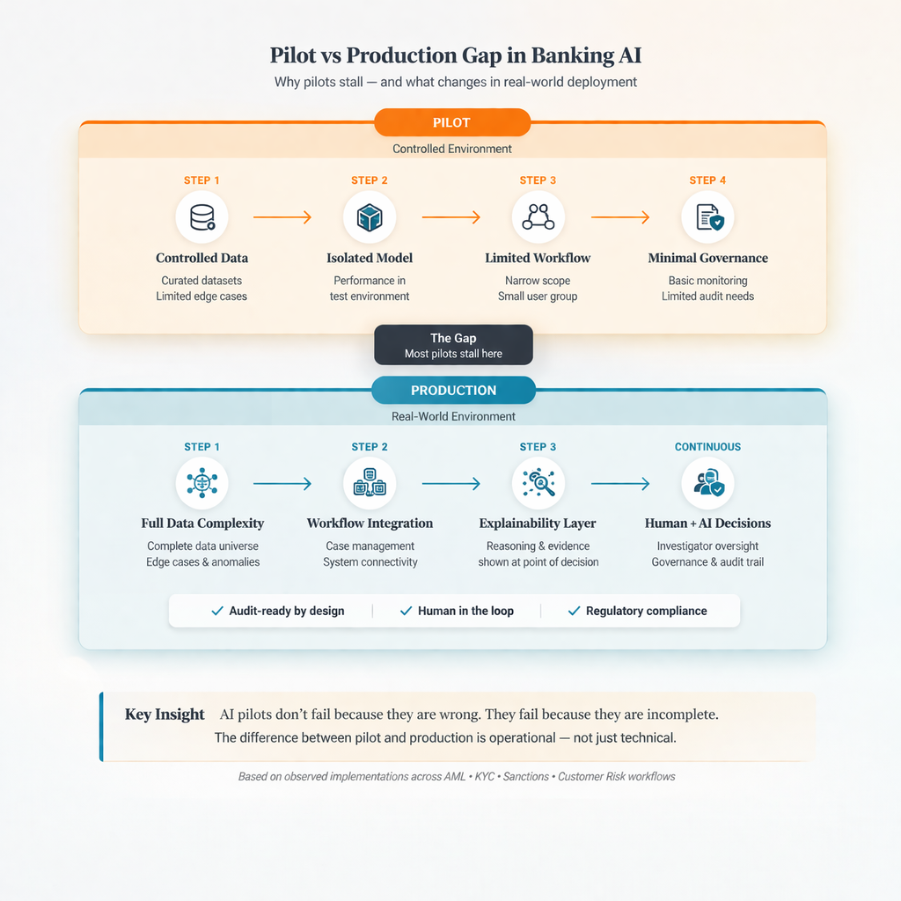
AI pilots do not fail because they are wrong. They fail because they are incomplete.
A large bank, mid-quarter.
The pilot has gone well. Early results show a reduction in manual effort. Alerts are being prioritized more effectively. The model has performed as expected in testing.
Then the questions begin.
An investigator reviewing a case pauses.
“Why was this flagged?”
A supervisor reviewing decisions asks:
“Would this hold up in an audit?”
A few weeks later, adoption is still limited to a small group. Investigators revert to familiar workflows for complex cases. The system continues to run, but it is no longer central to decision-making.
Nothing has broken.
But nothing has scaled.
This is how most AI pilots in banking actually fail. Not with a clear failure point, but with a gradual loss of relevance as they move closer to real-world conditions.
The gap is not technical. It is operational
Across banking workflows such as transaction monitoring, KYC onboarding, sanctions screening, and customer risk assessment, AI is being introduced to address very real pressures. Alert volumes are increasing. Investigation teams are stretched. Regulatory expectations continue to evolve.
In a pilot, these conditions are simplified. Data is curated. Scope is controlled. Edge cases are limited.
In production, complexity returns in full.
Systems must integrate with existing case management platforms. Outputs must align with how investigators assess risk. Decisions must be explainable, traceable, and defensible under audit.
The model may still perform well.
But the system around it often does not.
What changes between pilot and production
The shift from pilot to production is not about scale alone. It is about context.
In a pilot, the question is whether a model can solve a problem.
In production, the question becomes whether that solution fits into how decisions are actually made, reviewed, and governed.
An investigator does not interact with a model in isolation. They work within queues, case histories, escalation paths, and reporting requirements. Their decisions must remain defensible long after the case is closed.
If AI outputs do not align with this reality, they create friction rather than efficiency.
This is where most pilots begin to stall.
Trust is where scaling begins, or ends
In conversations with compliance leaders and risk teams, one pattern comes up consistently.
Adoption is rarely blocked by performance.
It is blocked by hesitation.
If a system cannot clearly explain:
- why a case was flagged
- what signals contributed to the decision
- how confident the system is
then every decision requires additional validation.
Over time, this shifts behavior. Investigators rely less on the system. Supervisors question its outputs. What began as an efficiency gain becomes a source of uncertainty.
As one senior banking executive noted in a recent industry discussion,
“If I cannot explain a decision, I cannot defend it. And if I cannot defend it, I cannot use it.”
This is the point where pilots stop progressing.
The false positive problem is, at its core, a trust problem
Reducing false positives is often the entry point for AI in AML and fraud monitoring.
On paper, the results can be compelling.
In practice, those gains only matter if investigators trust the outcomes.
When reasoning is visible and structured:
- false positives are dismissed more quickly
- true positives are easier to justify
- reviews become more consistent
When it is not:
- every case requires deeper manual review
- efficiency gains erode
- perceived risk increases
This is why many pilots show strong initial results but struggle to scale.
Governance is not something you add later
In many pilots, governance is treated as a later phase.
In production, it is foundational.
Institutions must be able to demonstrate:
- how models are trained and validated
- how decisions are made
- how outcomes are monitored
Leading banks are increasingly designing governance into systems from the outset. Audit trails, validation frameworks, and reporting structures are built as part of the architecture.
This reduces friction later and makes scaling possible.
Integration is where most progress slows down
Pilots are often built in isolation. Production systems must operate within existing infrastructure.
This includes integrating with:
- case management systems
- internal data pipelines
- regulatory reporting frameworks
Without this integration, even strong models remain disconnected from daily operations.
Investigators move between systems. Outputs are interpreted outside their natural workflow. Decisions become harder, not easier.
How leading institutions are approaching this differently
Across Tier 1 banks, the focus has shifted.
The question is no longer whether AI can work. It is whether AI can operate within the realities of a regulated environment.
This starts with designing around workflows, not tasks. Systems are built to support end-to-end processes such as transaction monitoring and onboarding.
Explainability is embedded early. Reasoning and evidence are surfaced alongside outputs, allowing decisions to be validated in real time.
Human oversight is clearly defined. AI supports decision-making, but accountability remains with individuals and teams.
Governance is built into the system. Auditability is part of how the system operates, not something added later.
A more useful question
The common question is how to move from pilot to production.
A more useful question is:
Was this pilot ever designed for production in the first place?
From what we’ve seen across implementations in banking environments, successful programs do not treat AI as a standalone capability. They treat it as part of the operating model.
This means aligning:
- model outputs with decision-making processes
- system design with investigator workflows
- AI capabilities with governance and audit requirements
When these elements are aligned early, scaling becomes significantly easier.
Where this becomes real
In practice, this transition is shaped by a series of small but critical decisions.
How outputs are presented to investigators.
How reasoning is surfaced at the point of use.
How decisions are recorded and audited.
Across implementations in AML, KYC, sanctions, and customer risk workflows, this is where most of the effort sits.
Not in improving model performance alone, but in ensuring that the system fits the conditions under which it must operate.
LatentBridge POV
From what we’ve seen across implementations, this is where most AI programs begin to diverge.
In environments where AI is treated as a standalone capability, progress often slows once the pilot phase ends. The model performs, but the system around it does not adapt. Investigators work around it rather than with it.
In contrast, where AI is designed as part of the operating workflow from the outset, adoption tends to look very different. Outputs are structured for action, reasoning is visible at the point of decision, and auditability is built into the process rather than added later.
This distinction, while subtle, is often what determines whether an initiative remains a pilot or becomes part of how the organization actually operates.
Closing thought
AI pilots are designed to demonstrate what is possible.
Production systems determine what is sustainable.
The difference between the two is not a matter of scaling technology alone. It is about aligning technology with how decisions are made, reviewed, and governed in real-world banking environments.
The difference is not always visible in early results. But it is what ultimately determines whether AI becomes part of how a bank operates, or remains an initiative that never moves beyond the pilot stage.

